A model for the integration of the multiple models within the Australian, national, Foundational Spatial Data Framework scenario.
1. Metadata
IRI |
|
Title |
FSDF Supermodel Specification |
Description |
This Model - the FSDF Supermodel - is the overarching data model that provides integration logic for all FSDF elements. It is based on the general-purpose Supermodel Model. |
Created |
2022-02-24 |
Modified |
2022-08-05 |
Issued |
2022-08-05 |
Creator |
|
Publisher |
|
License |
2. Preamble
2.1. Abstract
This Model - the FSDF Supermodel - is the overarching data model that provides integration logic for all FSDF datasets. It is based on the general-purpose Supermodel Model.
This model is effectively an update to the methodology of the Location Index (Loc-I) Project which introduced a generic spatial dataset model, the Loc-I Ontology, and a series of models for the specific FSDF datasets considered by the Loc-I Project. This Supermodel is a more formalised implementation of that Loc-I Project’s vision and also one that relies on updated background models, particularly GeoSPARQL, and updated or new dataset models.
2.2. Namespaces
This model is built on a "baseline" of Semantic Web models which use a variatey of namespaces. Prefixes for these namespaces, used throughout this document, are listed below. Additional namespaces and prefixes are listed in later sections of this document where they only apply to that section.
| Prefix | Namespace | Description |
|---|---|---|
|
Dublin Core Terms vocabulary namespace |
|
|
Generic examples namespace |
|
|
GeoSPARQL ontology namespace |
|
|
Web Ontology Language ontology namespace |
|
|
RDF Schema ontology namespace |
|
|
Sensor, Observation, Sample, and Actuator ontology namespace |
|
|
Simple Knowledge Organization System (SKOS) ontology namespace |
|
|
Supermodel Terms & Definitions Vocabulary |
2.3. Terms & Definitions
The following terms appear in this document and, when they do, the definitions in this section apply to them.
These terms are presented as a formal Semantic Web vocabulary at
- Backbone Model
-
An integrative, summary model, that allows for crosswalking of elements within the Component Models of a Supermodel.
- Background Model
-
A standard and common Semantic Web model used as "upper" or higher order/abstract model for all other Supermodel models to conform to when modelling something within the Background Model’s purview.
- Central Class
-
Central Classes are the generic data classes at the centre of Data Domains with high-level relationships between them defined in this supermodel.
These classes are taken from general standards - usually well-known international standards - and specialised and extended within implementation scenarios to cater for specific needs.
- Component Model
-
An individual models of something of importance within a Supermodel scenario.
- Data Domain
-
High-level conceptual areas within which Geosicence Australia has data.
These Data Domains are not themed scientifically - 'geology', 'hydrogeology', etc. - but instead based on parts of the Observations & Measurement [ISO19156] standard, realised in Semantic Web form in the SOSA Ontology, part of the Semantic Sensor Network Ontology [SSN].
Current Data Domain are shown in Figure 1.
- FSDF
-
:fsdf-defn - defined here
The Foundation Spatial Data Framework (FSDF): a project to deliver national coverages of the best available, most current, authoritative foundation data which is standardised and quality controlled. See https://link.fsdf.org.au.
- Knowledge Graph
-
A Knowledge Graph is a dataset that uses a graph data structure - nodes and edges - with strongly-defined elements.
- Linked Data
-
A set of technologies and conventions defined by the World Wide Web Consortium that aim to present data in both human- and machine-readable form over the Internet.
Linked Data is strongly-defined with each element having either a local definition or a link to an available definition on the Internet.
Linked Data is graph-based in nature, that is it consists of nodes and edges that can forever be linked to further concepts with defined relationships.
- Location Index
-
A project aiming to provide a consistent way to seamlessly integrate spatial data from distributed sources.
- Null Profile
-
:mull-profile-defn - defined here
A Null Profile is a Profile of a Standard that implements no additional constraints on the profile. A Null Profile’s purpose is to act as a conformance target for the Standard by supplying itemised requirements and machine-executable validators when the Standard itself cannot have these elements added to it.
- Ontology
-
In computer science and information science, an ontology encompasses a representation, formal naming, and definition of the categories, properties, and relations between the concepts, data, and entities that substantiate one, many, or all domains of discourse.
The word ontology was originally defined as "the branch of philosophy that studies concepts such as existence, being, becoming, and reality". and the computer science term is derived from that definition.
- Profile
-
https://www.w3.org/TR/dx-prof/#dfn-profileA data standard that constrains, extends, combines, or provides guidance or explanation about the usage of other standards.
This definition includes what are sometimes called "data profiles", "application profiles", "metadata application profiles", or "metadata profiles". In this document, "profile" and these other variants are all referred to as just "profiles".
NoteThis definition has been taken from [PROF] and altered slightly for clarity here
- Semantic Web
-
The World Wide Web Consortium's vision of an Internet-based web of Linked Data.
Semantic Web is used to refer to something more than just the technologies and conventions of Linked Data; the term also encompasses a specific set of interoperable data models - often called ontologies - published by the W3C, other standards bodies and some well-known companies.
The 'semantic' refers to the strongly-defined nature of the elements in the Semantic Web: the meaning of Semantic Web data is as precisely defined as any data can be.
- Vocabulary
-
A managed codelist or taxonomy of concepts.
3. Introduction
This Supermodel is based on previous work from the Location Index (Loc-I) Project. For clarity, that the Loc-I Project is described, followed by how this Supermodel inherits from it.
3.1. Loc-I Project
The Location Index (LOC-I) project, established in 2018, created a methodology, data models and an informal framework to allow for a consistent way to seamlessly integrate spatial data from distributed sources. The target was Australian spatial data "of national significance", meaning most - initially all - of the data considered was Australian Federal government data.
See the project website, http://www.ga.gov.au/locationindex, for more project information.
3.2. Loc-I Technical Implementation
The technical implementation of Loc-I was based on Semantic Web principles allowing datasets to be published as Linked Data independently, by data holders - different government departments, companies etc. - and consumed with minimal effort required for integration.
The technical implementation relied on data from the various datasets sharing common patterns, principally, how the datasets packaged their content and how real-world objects, their spatiality and non-spatial properties were modelled.to this end, a number of Background Models were used, to which all Loc-I dataset models - here called Component Models - conformed. Additionally, a Loc-I Ontology was also created which both included modelling elements needed for the LocI Project that were not present in Background Models and which was to act as a conceptual, if not technical, conformance target for all Component Models.
Figure 2 below shows the original detailed architecture diagram used to explain Loc-I’s parts from 2018 - 2021.
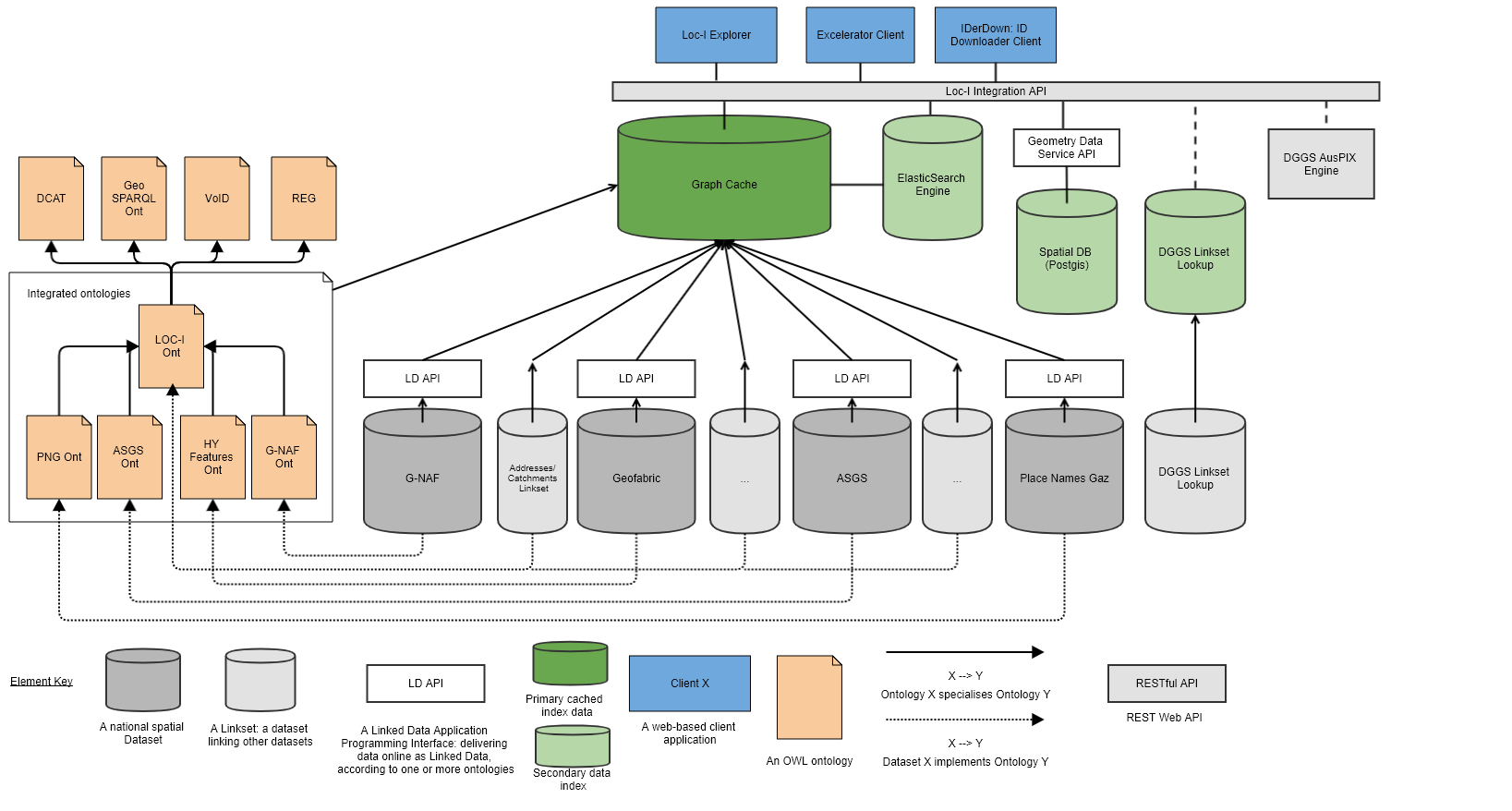
3.3. Loc-I to Supermodel
The FSDF Project has adopted a more rigorously defined Supermodel concept to formalise things of importance to Loc-I-like work but which the Loc-I Project didn’t define. For example, the categorisation of relevant models as Background Models, Component Models and so on. The major differences/additions are:
-
Formalised terminology
-
Of general relevance within the implementation scenario
-
See the Terms & Definitions section.
-
-
Model categorisation
-
For the different types of models within the scenario, for example, Background Models, Component Models
-
-
Explicit integration
-
By explicitly defining a Backbone Model for each scenario deployment, the Supermodel conventions indicate precisely what minimum requirements for Component Models are to be able to be integrated
-
-
Validatable profiling instead of model specialisation
-
Loc-I relied on defining an ontology to which datasets were expected to conform
-
Supermodel implements a Profile of Background Models to which Component Datasets mush conform
-
The Profile provides executable data validators
-
In addition to these model/methodological changes, this particular Spuermodel deployment has updated scenario-specific things, in particular:
-
Use of GeoSPARQL 1.1
-
The Loc-I Project motivated extensions to the GeoSPARQL 1.0 ontology which were captured in the GeoSPARQL Extensions Ontology (GeoX). That ontology was then used by many Loc-I Project dataset models (Component Models)
-
The update to GeoSPARQL, GeoSPARQL 1.1, absorbed many of these updates and so there is no longer a need to use GeoX
-
-
Collection-based Feature organisation
-
Several Loc-I dataset models (Component Models) used specialised properties to indicate aggregations of Feature, e.g. the ASGS Ontology’s
aggregatesTo&isAggregationOf -
The latest issue of the ASGS dataset within this Supermodel, online at https://linked.data.gov.au/dataset/asgsed3, uses only Collection membership (all Meshblock Features are members of the Meshblocks Feature Collection) and standard topological relations, e.g. each SA2 is
geo:sfWithinan SA3 -
This takes advantage of GeoSPARQL 1.1’s collections which match OGC API structures and removes non-standard spatial object relations
-
specialised Feature aggregations may be re-added to objects within this Supermodel, if required
-
-
Topological querying instead of Linksets
-
Loc-I Linksets are datasets that declare topologicla relations between Features
-
GeoSPARQL allows topological relationships to be calculated using topologicla functions
-
Loc-I Project established only a limited set of Linksets, e.g. the Current Addresses to 2016 Mesh Blocks Linkset
-
This Supermodel deployment includes a cache of all datasets, https://cache.linked.fsdf.org.au, on which topological queries across all datasets can be performed
-
To conclude this Loc-I/Supermodel relations, here is a table mapping elements and terminology.
| Loc-I | FSDF Supermodel | Notes |
|---|---|---|
Upper ontologies |
The Supermodel precisely lists Background Models in Background Models where Loc-I left their discovery to general documentation or dataset model imports |
|
The Backbone Model profiles GeoSPARQL 1.1 and thus incorporates equivalent (updated) GeoX modelling. Loc-I Ontology Linksets are not used. Loc-I Ontology Datasets are replaced with Backbone Model profiling of DCAT |
||
The FSDF Supermodel lists the Component Models defined to be within it formally in this Supermodel document |
||
The new model is a more standards-based form of the previous one and all aspects of the original model are covered by the new |
||
The current delivery of the ASGS at https://asgs.linked.fsdf.org.au uses no properties other than those already in the Backbone Model therefore no custom Component Model is needed |
||
unchanged |
The Geofabric data online at https://geofabric.linked.fsdf.org.au currently uses only one element of the Geofabric Ontology, the property |
|
unchanged |
While not an official original Loc-I dataset, Placenames was implemented in Loc-I style at https://fsdf.org.au/dataset/placenames/. It has been brought in to the Supermodel as a standard Component Model using the same ontology, albeit with updates |
|
Geometry Data Service |
Loc-I build a non-Semantic geometry data service for some cross-dataset spatial queries. Supermodel implements a total cache of all Component Models' content in semantic form for GeoSPARQL spatial querying and other semantic querying |
The Loc-I project also implemented a series of custom clients for Loc-I systems. These clients demonstrated
-
downloading lists of Loc-I identifiers (IRIs) for classes of object for offline use
-
reapportioning numerical observations data formed according to one set of geometries to another
-
finding Features that intersect with a given point or Feature
Some of this functionality is now available through the SPARQL Endpoints available for all FSDF APIs and also the API accessing a cached copy of all data.
Functionality not covered by SPARQL Endpoints is being implemented in new FSDF clients which Geoscience Australia will release when ready.
4. Supermodel
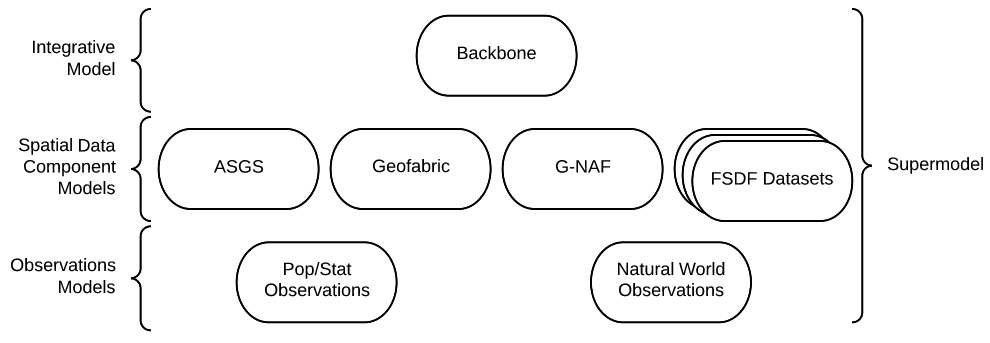
4.1. Overview
This Section describes the structure of this Supermodel, aspects of the modelling involved and how to use this Supermodel. Following Sections describe the elements of the Supermodel in detail.
4.2. Structure
The high-level structure of this Supermodel consists of:
-
-
Standard and common Semantic Web models used as "upper" or higher order/abstract model for all other Supermodel models to conform to when modelling something within the Background Model’s purview.
-
Models such as the Provenance Ontology [PROV] model provenance and all Supermodel models follow it when doing provenance work
-
GeoSPARQL [GEO] serves as the background model for spatial objects - features and their geometries
-
-
-
This is a profile of the Background Models and includes validators
-
Data must conform to this model in order to be considered within this Supermodel
-
This model is a bare minimum: Component Models can, and already do, extend beyond this model to cater for their specific needs
-
-
-
These are individual models for datasets within this Supermodel
-
Not all dataset require a Component Model, for example, the ASGS is currently modelled using Backbone Model elements only
-
-
-
Vocabularies that support the Backbone and Component models
-
They must conform to the VocPub Profile of SKOS
-
They may contain specialised elements beyond VocPub/SKOS too
-
Further details of and definitions for these elements are provided in the Terms & Definitions section, above, and in the Supermodel Model.
The next section deals with some aspects of how the models are created.
4.3. Modelling Methods
The modelling language/system used for all Supermodel elements expressed formally is the Web Ontology Language [OWL]. OWL diagramming is used for formal model images and, when it is, this is noted in the figure description. The figure below is a key for all OWL diagramming elements.
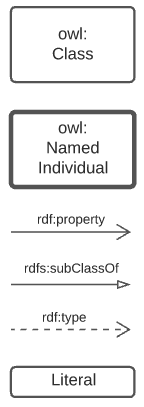
4.3.1. Object Modelling
The elements from the above subsection are shown in relation to one another in the figure below.
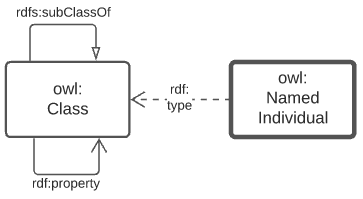
The elements shown above are identified with prefixed IRIs that correspond to entries in the Namespace Table. A short explanation of the diagram key elements is:
-
owl:Class- represents any conceptual class of objects. Classes are expected to contain individuals - instances of the class - and the class, as a whole, may have relations to other classes -
owl:NamedIndividual- an individual of anowl:class. For example, for the class ships, an individual might be Titanic -
rdf:property- a relationship between classes, individuals, or any objects and Literals -
rdfs:subClassOf- anrdf:propertyindicating that the domain (from object) is a subclass of the range (to objects). An example is the class student which is a subclass of person: all students are clearly persons but not vice versa -
rdf:type- the property that related anowl:NamedIndividualto theowl:Classthat it’s a member of -
Literal- a simple literal data property, e.g. the string "Nicholas", or the number 42. Specific literal types are usually indicated when used
The remaining diagrams in this document use extensions to this basic model, for example Figure 3 uses colour-coded specialised forms of owl:Class (subclasses of it).
4.3.2. Provenance
General provenance/lineage information about anything - a rock sample, a dataset, a term in a vocabulary etc. - is described using the Provenance Ontology [PROV] which views everything in the world as being of one or more types in Figure 3.
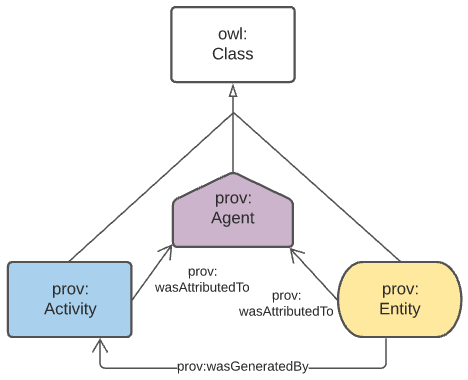
According to PROV, all things are either a:
-
prov:Entity- a physical, digital, conceptual, or other kind of thing with some fixed aspects -
prov:Agent- something that bears some form of responsibility for an activity taking place, for the existence of an entity, or for another agent’s activity -
prov:Activity- something that occurs over a period of time and acts upon or with entities
While not often in front of mind for objects in any Data Domain, provenance relations always apply, for example: a sosa:Sample within the Sampling domain is a prov:Entity and will necessarily have been created via a sosa:Sampling which is a prov:Activity. Another example: an sdo:Person related to a dcat:Dataset via the property dcterms:creator in the DataCataloging domain is a specialised form of a prov:Agent related to a prov:Entity via prov:wasAttributedTo.
4.4. Ensuring Data Conformance
First the requirements for data to conform to are described, then how to test conformance in the Validation section.
4.4.1. Conformance Requirements
Data wishing to be used within this Supermodel must conform to:
-
Relevant Background Models
-
The Backbone Model
-
Perhaps a Component Model
Relevant Background Models
All data within the Supermodel will need to conform to at least some Background Models. Working out which ones are relevant is done by looking at the conceptual scope of the various listed Background Models and comparing the conceptual scope of the data to them.
For example, if the data is spatial - and most of it will be - it will need to conform to GeoSPARQL [GEO]. If it’s observations information, Data Cube [DQ].
Many Background Models are generic and have a wide scope and thus most data will need to conform to most Background Models.
For example, if the data contains provenance information, regardless of whether it’s a spatial or observations dataset, it will need to conform to the Provenance Ontology [PROV].
Backbone Model
All data will need to conform to the Backbone Model as this model is used to ensure all data can work together.
This model is only concerned with minimum requirements for data, so data conforming to this model may have any other things in it - details specific to that dataset’s concern - that are un-handled/unknown in the Backbone Model. That’s fine, as long as the minimal requirements are met.
Component Model
Many datasets will have a Component Model implemented for them. If they due, obviously data within that dataset must conform to it. If no Component Model has been implemented, it means that dataset is a direct implementation of the Backbone Model and need only conform to that.
4.4.2. Validation
To ensure that data within a dataset conforms to the models it needs to, automated validation of data must occur. This Supermodel implements validators for the Backbone Model that must be used to test data with.
This Supermodel is also either obtaining or implementing validators for all Background Models over time. Validators implemented for Background Models in this Supermodel are implemented within Null Profiles of them since most of the Background Models are previously defined controlled standards that cannot have all the profiling elements relevant to Supermodels just added to them.
4.5. How to use this Supermodel
This Supermodel provides a general structure for datasets that want to integrate within the FSDF Data Platform. The common tasks you might perform with the Supermodel are:
-
Model a new dataset as an FSDF Supermodel generic dataset
-
Validate new dataset data according to the FSDF Supermodel
-
Create an extended/specialised Component Model for a dataset
-
Validate extended/specialised new dataset data according to the extended/specialised FSDF Supermodel Component Model
-
Create a dataset of observations - population/statistical or natural world - linked to Component Models
Detailed suggestions as to how to achieve these tasks are given below.
4.5.1. 1. Model a new dataset
Individual datasets are modelled as Component Models. The most basic of Component Models contain Dataset, FeatureCollection & Feature classes modelled using the DCAT & GeoSPARQL Background Models with certain relations. The details of this modelling are given in the first part of the Component Models section.
To model a highly specialised dataset, you will need to be able to implement both the most basic Component Model elements but also model the specialised elements relevant to your dataset. No specific guidance about your dataset can be given here however the Component Models section does indicate existing datasets that contain a large amount of specialisation that you may draw inspiration from.
In all cases, you can use the tools listed in the Validators section to test any data you’ve created to see if it really is valid according to this Supermodel.
4.5.2. 2. Validate new dataset
Data validators are available, for all elements of this Supermodel, so you can use them to validate your data. See the Validators section.
4.5.3. 3. Create an extended/specialised 'Component Model'
As per subsection 1. above, we can’t give specific details about specialised modelling here since we don’t know about your particular dataset however we can both indicate existing specialised datasets (see the start of the Component Models section), and we can make a few general points:
-
this Supermodel is concerned with the modelling of spatial datasets as Component Models with
Dataset,FeatureCollection&Featurewith certain relations between them -
most specialisation is likely to occur by adding special properties to
Featureinstances-
for example, the
Featureinstances within the FSDF’s Power StationsFeatureCollectioncontain properties relevant to power generation, such asprimaryfuelTypeindicating coal, biogas etc., and these are important for knowledge of Power Stations but don’t affect the general spatial feature modelling of this Supermodel in any way
-
-
spatial relations - between
Featureinstances within oneFeatureCollectionor even acrossDatasetinstances - are expected and can be modelled using GeoSPARQL’s Simple Features Topological Relations Family.-
No custom modelling is likely required for standard spatial relations
-
-
The geometries of
Featureinstances can be represented in several ways andFeatureinstances can have multiple geometries-
Boundaries at different levels of resolution may be given or geometries with different roles, e.g. high and low tide boundaries
-
4.5.4. 4. Validate extended/specialised new dataset data
As per section 2. above, see the Validators section. Of course, your specialised modelling won’t have a validator for it, however you can certainly ensure that your new data is valid according to this Supermodel.
4.5.5. 5. Create a dataset of observations
The spatial datasets within this Supermodel are intended to present spatial objects that observations' data can be referenced against. For example, Australian census data is keyed to the Mesh Blocks and other spatial areas of the ASGS dataset, water data in the Bureau of Meteorology’s AWRIS system are keyed to catchments within the Geofabric dataset.
You can create your own observations data and key them to any datasets that exist within this Supermodel or to datasets that you make that are compatible with this Supermodel’s elements.
5. Background Models
Background Models are:
standard and common Semantic Web model used as "upper" or higher order/abstract model for all other Supermodel models to conform to when modelling something within the Background Model’s purview.
5.1. List
The particular Background Models in this FSDF Supermodel are given in the table below, with a description of the conceptual area they cover indicated as 'Domain', to assist in assessment of their relevance to Supermodel data.
| Background Model | Reference | Domain |
|---|---|---|
Web Ontology Language |
General Modelling: all the other Background Models are OWL models |
|
schema.org |
General Modelling: Agents (People & Organisations), licensing etc. |
|
Data Catalog Vocabulary |
Dataset Metadata |
|
The Provenance Ontology |
Data Metadata: attribution of data to owners/publishers etc. Data lineage: what things datasets derive from |
|
GeoSPARQL 1.1 |
Spatiality: Feature/Geometry links, topological relations, spatial scalar values (e.g. area) |
|
Data Cube Vocabulary |
Data Dimensions: for observations data, e.g. population census |
|
Sensor, Observation, Sample, and Actuator (SOSA) |
Data Dimensions: for spatial and natural-world data, e.g. from satellites |
|
Simple Knowledge Organization System |
Vocabularies |
|
Vocabulary Publications Profile of SKOS |
A profile of SKOS requiring certain properties for vocabularies and their elements |
5.2. Domain Details
The domains for each of the Background Models are noted in the table above, however here now are indicative models for each of then indicating the main classes and properties of concern within the domain.
5.2.1. General Modelling
All of the Background Models, the Backbone Model and all other Supermodel models use the Web Ontology Language, OWL, for their modelling structures. While a description of OWL is out-of-scope for this document, below is given a key for the main OWL elements seen in subsequent figures.
5.2.2. Dataset Metadata
Metadata for datasets within this Supermodel is based on the Data Catalog Vocabulary [DCAT] with elements of The Provenance Ontology [PROV] for a few purposes, such as Data/Agent relations. Note that DCAT recommends this use of PROV. The figure below gives an informal overview of the concerns in this domain.
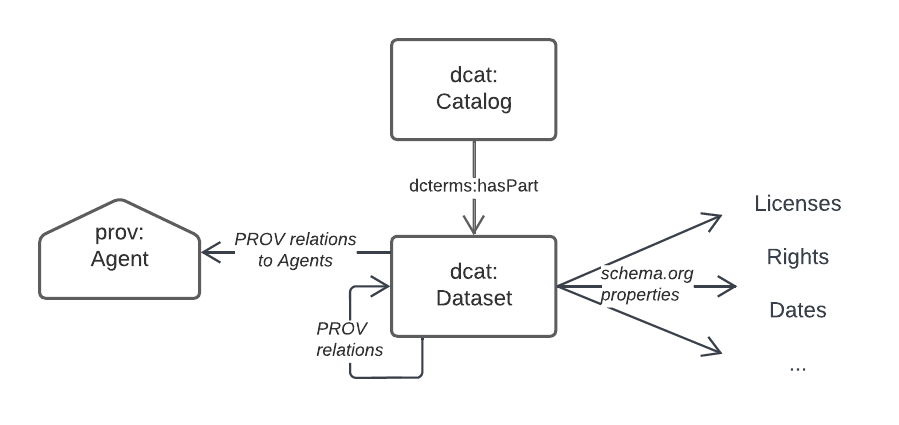
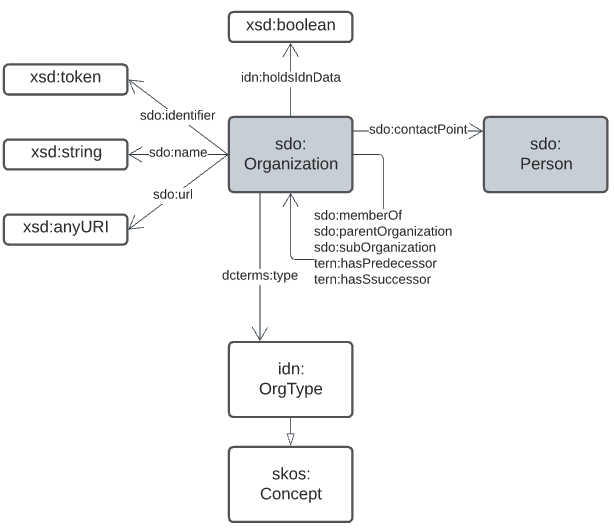
Specifics properties for dataset-level metadata, such as license, copyright notices, who the publisher is etc. are mostly taken from schema.org which is a general-purpose OWL (or at least OWL-compatible!) vocabulary of classes and properties.
schema.org is also used for Agent/Agent relations, as per the figure below.
5.2.3. Spatialiaty
This Supermodel’s core concern of modelling spatiality is based on use of the GeoSPARQL 1.1 Standard [GEO] which concerns itself with the elements in the figure below. The figure is a part reproduction of GeoSAPRQL’s overview diagram.
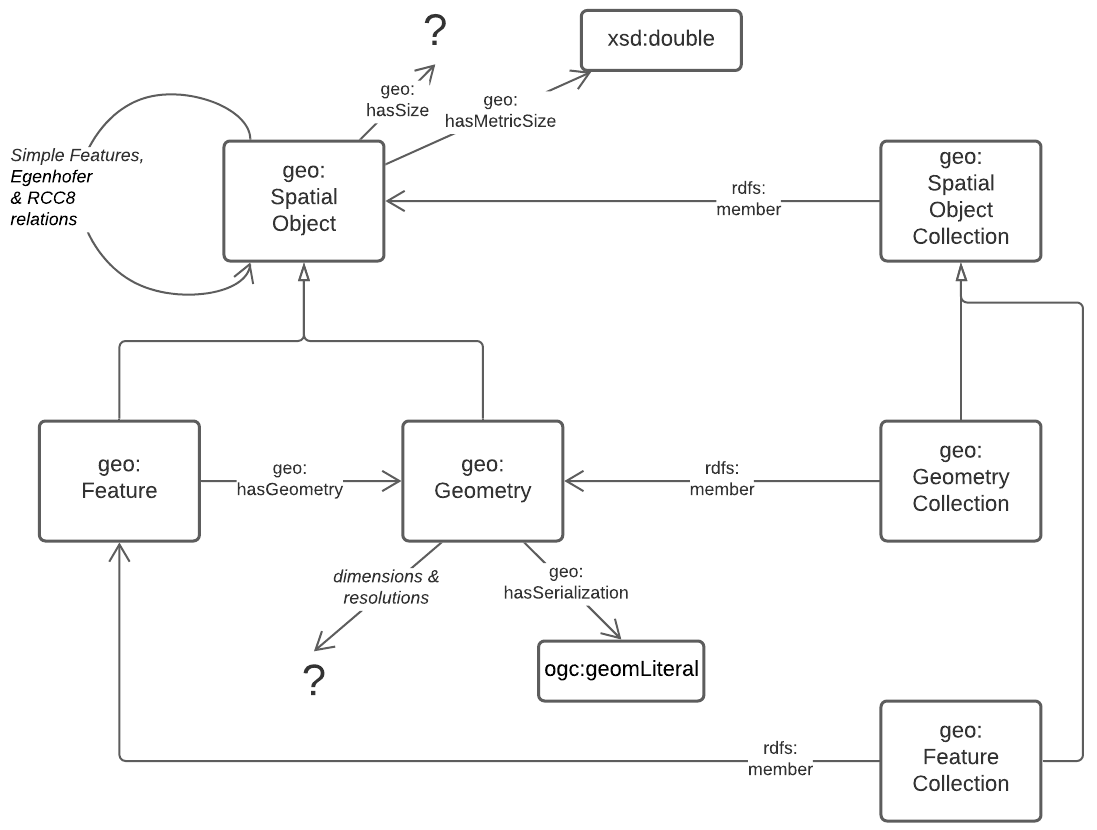
Essentially all spatial relations between objects and the associations of objects with spatiality (Features with Geometries) and the details of Geometry data are defined by GeoSPARQL.
5.2.4. Data Dimensions
The dimensions of data are, in general, modelled in relation to observations according to the Data Cube Vocabulary [QB], however the dimensions (observable properties) of spatial and real-world objects is modelled using Sensor, Observation Sampling & Actuation (SOSA) ontology within the Semantic Sensor Networks [SSN] standard. SOSA is, within this Supermodel at least, a domain-specialised version of QB.
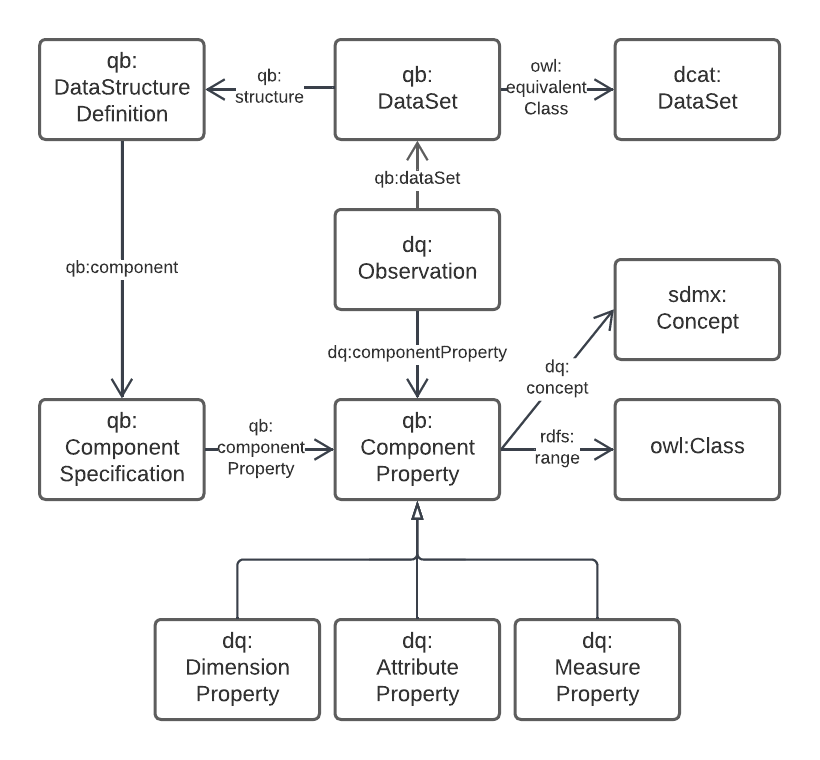
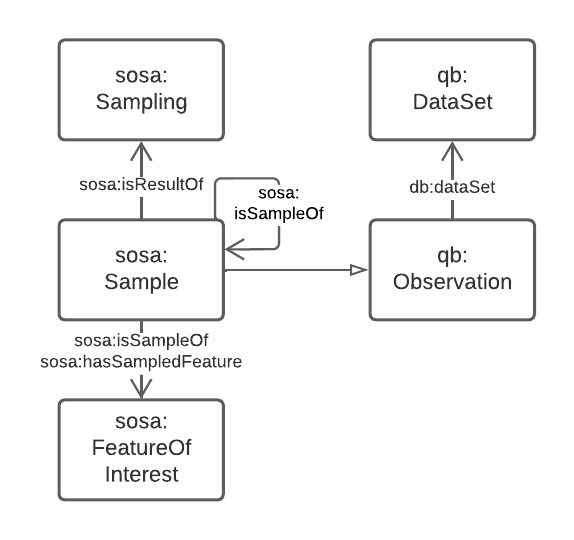
The separate modelling for spatial/real-world features' properties is due to widespread use of SOSA for observations in that domain, for example the Geoscience Australia Samples catalogue (http://sss.pid.geoscience.gov.au/sample/).
The net effect of both QB and SOSA is to define data types for and observable properties/dimensions that observations are of.
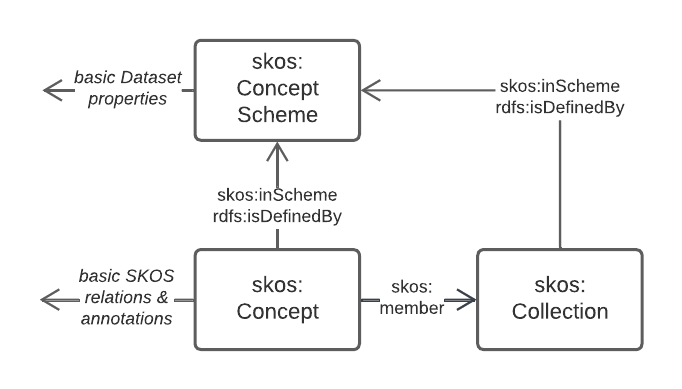
5.2.5. Vocabularies
Many of the models in this Supermodel rely on vocabularies of individual items, for example Data/Agent relations rely on vocabularies of Agent roles. When vocabularies are modelled, this Supermodel uses a profile of the Simple Knowledge Organization System, [SKOS], called VocPub [VOCPUB]. VocPub just requires certain metadata, allowed by bot not mandated by SKOS, to be present within vocabularies for data management purposes. At a whole-of-vocabulary level, VocPub requires very similar metadata to DCAT, thus a Vocabulary appears as a form of Dataset.
All the current FSDF vocabularies at https://linked.fsdf.org.au/vocab conform to VocPub.
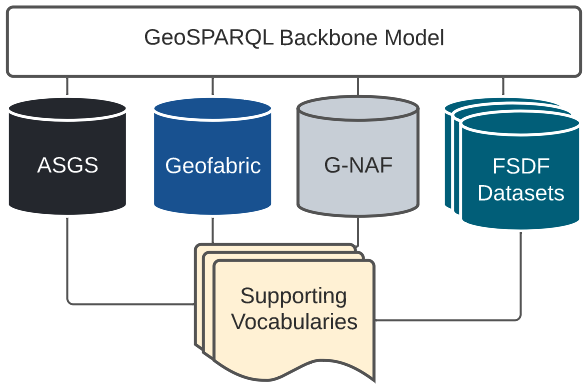
6. Backbone Model
The Backbone Model of this Supermodel is the model to which all data MUST conform. The model is a profile of the Background Models, which means it implements no new modelling elements of its own but just constrains existing elements in the Background Models. Thus, anything that conforms to the Backbone Model will conform to the Background Models also. This form of profiling is formally defined in The Profiles Vocabulary [PROF].
This Backbone Model is quite "lite" in that it only has comparatively few requirements. This is due to its role: to ensure that all data in the Supermodel exhibits a minimum set of properties and patters for interoperability. the Backbone Model doesn’t try to model all thins within all sub-domains of this Supermodel: that is the job of the various Component Models.
This Backbone Model is defined at:
The profile’s main elements are articulated here for the completeness of documentations.
6.1. Definition
This is part of the formal definition of this profile:
<https://linked.data.gov.au/def/fsdf-backbone>
a prof:Profile ;
sdo:name "FSDF Backbone Model Profile" ;
sdo:description "This is a profile of DCAT, GeoSPARQL & VocPub to be used as a conformance target for data within the FSDF Supermodel"@en ;
prof:profileOf
<https://www.w3.org/TR/vocab-dcat/> ,
<http://www.opengis.net/doc/IS/geosparql/1.1> ,
<https://www.w3.org/TR/vocab-data-cube/> ,
<https://www.w3.org/TR/vocab-ssn/> ,
<https://w3id.org/profile/vocpub> ;
...
.This code identifies the profile, https://linked.data.gov.au/def/fsdf-backbone, and, appart from basic human-readable annotations, states that it is a profile of (profileOf) the main Background Models.
The full profile definition, online at https://linked.data.gov.au/def/fsdf-backbone, gives further details such as the listing of resources within the profile, which includes its specification & validators - also described below.
6.2. Requirements
Here the requirements for data to conform to this profile are listed. The Requirements are identifies (GM1 etc.) and they are referenced by validation rules in the Validation section described below. Note that some of these Requirements reference whole other Standards and Profile so that all the Requirements from them are relevant.
The capitalised, italicised words such as MUST, MAY etc., have meanings as per [RFC2119].
The rdf namespace referred to is http://www.w3.org/1999/02/22-rdf-syntax-ns#.
| Domain | ID | Name | Definition |
|---|---|---|---|
General Modelling |
GM1 |
OWL Conformance |
Data must conform to OWL |
GM2 |
Class Modelling |
Classes of object MUST be modelled as |
|
GM3 |
Property Modelling |
Properties and predicates MUST be modelled as either |
|
Dataset Metadata |
DM1 |
DCAT Conformance |
Data must conform to DCAT |
DM2 |
Dataset Mandatory Properties |
|
|
DM3 |
Dataset Agents |
|
|
DM4 |
Dataset Provenance |
|
|
DM5 |
Dataset Spatiality |
|
|
DM6 |
Dataset Feature Collections |
|
|
Spatiality |
S1 |
GeoSPARQL Conformance |
Spatial data MUST conform to the GeoSPARQL 1.1 Standard |
S2 |
Feature Collection Mandatory Properties |
|
|
S3 |
Dataset Spatiality |
|
|
S4 |
Feature Collection Features |
|
|
S5 |
Feature Mandatory Properties |
|
|
Data Dimensions |
DD1 |
Data Cube Vocabulary Conformance |
Non-physical sciences observations data must conform to Data Cube Vocabulary |
DD2 |
SOSA Conformance |
Physical sciences observations data must conform to the SOSA ontology |
|
Vocabularies |
V1 |
VocPub Conformance |
Vocabularies MUST conform to the VocPub Profile of SKOS |
6.3. Validation
To prove that data does conform to this Backbone Model, it must be validated. Since all the expected data for this Supermodel is RDF data, SHACL [SHACL] validation may be used.
This Profile presents its own validator which only includes tests for the rules specific to this profile and not those of the things this Profile profiles. However, a compounded validator is also given below which includes this Profile’s validator and validators from all the Standards and Profiles that this Profile profiles, that have validators. The Standards' and Profiles' are also listed individually.
|
Note
|
Since of the Standards that this Profile Profiles do not present SHACL validators, we use Null Profiles for them where a Null Profile is a Profile that implements no constrains on the Standard profiles and exists only to provide a validator for it. |
For total validation, the compounded validator should be used. For partial validation, use each of the individual ones.
6.3.1. Process
To validate RDF data, a SHACL validation tool, such as pySHACL (online tools for validation exist too, see [tooling] below), is used with the data to be validated and the validator as inputs. The data to be validated must include all the elements necessary for validation, for example, if a valid Dataset/Agent relation includes the requirement for the Agent to be classed as an sdo:Person or an sdo:Organization then the data to be validated must declare this classification, rather than leaving it up to external resources.
|
Note
|
Validators that find nothing to validate will return true, so if the data to be validated contains no instances fo classes known to the validator, no sensible result will be obtained. |
Regarding scale: validation is a resource-intensive task, so large datasets should not be validated without dedicated systems. It is probably appropriate to validate only a sample of Dataset contents, especially if the content is produced by a script or someother method that makes similar Feature Collections & Features.
6.3.2. Validators
| Standard / Profile | Validator | IRI |
|---|---|---|
Backbone Model |
Backbone Model Validator |
|
Backbone Model |
Backbone Model Compounded Validator |
https://linked.data.gov.au/def/fsdf-backbone/validator-compounded |
DCAT |
DCAT Null Profile Validator |
|
GeoSPARQL 1.1 |
GeoSPARQL Validator |
|
Data Cube Vocabulary |
Data Cube Vocabulary Null Profile Validator |
|
SOSA |
SOSA Null Profile Validator |
|
VocPub |
VocPub Validator |
6.3.3. Tooling
Several online SHACL validation tools exist that may be used with the validators above:
-
SHACL Playground
-
EU SHACL Validator
We recommend either the public RDFTools Online tool, since it is actively maintained, and includes some of the validators listed above, or the Geoscience Australia copy of RDFTools with all the validators above preloaded:
-
Public RDFTools Online
-
GA RDFTools Online
-
link needed from GA
-
7. Component Models
This section contains the details of the various Component Models used for the individual datasets within the FSDF Data Platform.
Several datasets in the Platform use only the Backbone Model for their model and thus require no specialised Component Model. It is expected that many straightforward spatial dataset may be able to be created as plain Backbone Model-only datasets in this way if the only contain collections of names Features without special relationships or properties.
The table below lists the current major Datasets in the FSDF Data Platform and their Component Models or use of the Backbone Model.
| Dataset | Persistent Identifier | Model | Notes |
|---|---|---|---|
Australian Statistical Geographies Standard, Edition 3 |
Previous editions of the ASGS dataset used specialised Component Models, in particular the ASGS Ontology, but the current Edition 3 uses only the Backbone Model |
||
Australian Hydrological Geospatial Fabric (Geofabric), v3 |
The Geofabric Ontology is a very small specialisation of the Backbone Model that only declares specialised classes of |
||
(Australian) Geocoded National Address File (G-NAF) |
The G-NAF uses a highly specialised Component Model that models many aspects of Addresses |
||
Placenames |
The Place Names ontology originally made for the Loc-I Project is currently used, however a future version might use parts of the ANZ National Address Model which covers Place Names also |
The table below lists the current smaller "FSDF" Datasets in the FSDF Data Platform.
| Dataset | Persistent Identifier | Model | Notes |
|---|---|---|---|
Electrical Infrastructure |
|||
Facilities |
|||
Sandgate example |
This dataset does not have a Persistent Identifier as it’s an example dataset only |
8. Supporting Vocabularies
The vocabularies supporting the Component Models of the Datasets listed in the Section above are all from one of the following types:
-
Well-known, public vocabularies
-
For example, the vocabulary of Role types for Agents with respect to Datasets is the ISO’s Role Code vocabulary
-
-
Vocabularies within Component Models
-
For example, the various vocabularies within the ANZ National Address Model, such as Address Component Types
-
-
Vocabularies created for Dataset within this Supermodel not within Component Models
-
For example https://linked.data.gov.au/def/fsdf/ground-relations [FSDF Ground Relations]
-
All vocabularies are discoverable by inspecting the data that refers to them. Those within Component Models are also discoverable via their models, but those in Category 3. are also discoverable via the FSDF Vocabulary Server:
References
-
[ABIS] Department of Agriculture, Water and the Enviroment, Australia Biodiversity Information Standard (ABIS), Australian government Semantic Web Standard (2022-01-14). https://linked.data.gov.au/def/abis
-
[DCTERMS] DCMI Usage Board, DCMI Metadata Terms, A DCMI Recommendation (2020-01-20). https://www.dublincore.org/specifications/dublin-core/dcmi-terms/
-
[DCAT] World Wide Web Consortium, Data Catalog Vocabulary (DCAT) - Version 2, W3C Working Group Note (04 February 2020). https://www.w3.org/TR/vocab-dcat/
-
[GEO] Open Geospatial Consortium, OGC GeoSPARQL - A Geographic Query Language for RDF Data, Version 1.1 (2021). OGC Implementation Specification. http://www.opengis.net/doc/IS/geosparql/1.1
-
[ISO19156] International Organization for Standardization, ISO 19156: Geographic information — Observations and measurements (2011)
-
[OGCAPI] Open Geospatial Consortium, _OGC API - Features, overview website (2022). OGC Implementation Specification. https://ogcapi.ogc.org/features/. Accessed 2022-03-03
-
[OGCLDAPI] SURROUND Australia Pty Ltd, OGC LDA PI Profile, Profiles Vocabulary Profile (2021). https://w3id.org/profile/ogcldapi
-
[OWL] World Wide Web Consortium, OWL 2 Web Ontology Language Document Overview (Second Edition), W3C Recommendation (11 December 2012). https://www.w3.org/TR/owl2-overview/
-
[PROF] World Wide Web Consortium, The Profiles Vocabulary, W3C Working Group Note (18 December 2019). https://www.w3.org/TR/dx-prof/
-
[PROV] World Wide Web Consortium, PROV-O: The PROV Ontology, W3C Working Group Note (18 December 2019). https://www.w3.org/TR/prov-o/
-
[RDF] World Wide Web Consortium, RDF 1.1 Concepts and Abstract Syntax, W3C Recommendation (25 February 2014). http://www.w3.org/TR/rdf11-concepts/
-
[RDFS] World Wide Web Consortium, RDF Schema 1.1, W3C Recommendation (25 February 2014). https://www.w3.org/TR/rdf-schema/
-
[RFC2119] Internet Engineering Task Force. Key words for use in RFCs to Indicate Requirement Levels, Best Current Practice (March 1997) https://tools.ietf.org/html/rfc2119
-
[QB] World Wide Web Consortium, The RDF Data Cube Vocabulary, W3C Recommendation (16 January 2014). https://www.w3.org/TR/vocab-data-cube/
-
[SDO] W3C Schema.org Community Group, schema.org. Community ontology (2015). https://schema.org
-
[SSN] World Wide Web Consortium, Semantic Sensor Network Ontology, W3C Recommendation (19 October 2017). https://www.w3.org/TR/vocab-ssn/
-
[SKOS] World Wide Web Consortium, SKOS Simple Knowledge Organization System Reference, W3C Recommendation (18 August 2009). https://www.w3.org/TR/skos-reference/
-
[TTL] World Wide Web Consortium, RDF 1.1 Turtle Terse RDF Triple Language, W3C Recommendation (25 February 2014). https://www.w3.org/TR/turtle/
-
[VOCPUB] SURROUND Australia Pty Ltd, VocPub, Profile of SKOS (14 June 2020). https://w3id.org/profile/vocpub